Context Is Everything: Managing Tokens, Memory, and Prompts for Multi-Agent Systems
If I had to simplify the work of integrating agents into one phrase, it would be this:
Context is everything.
The models are powerful, the APIs are stable, but context determines whether your agent feels like a helpful collaborator or a confused chatbot.
What We Mean by “Context”
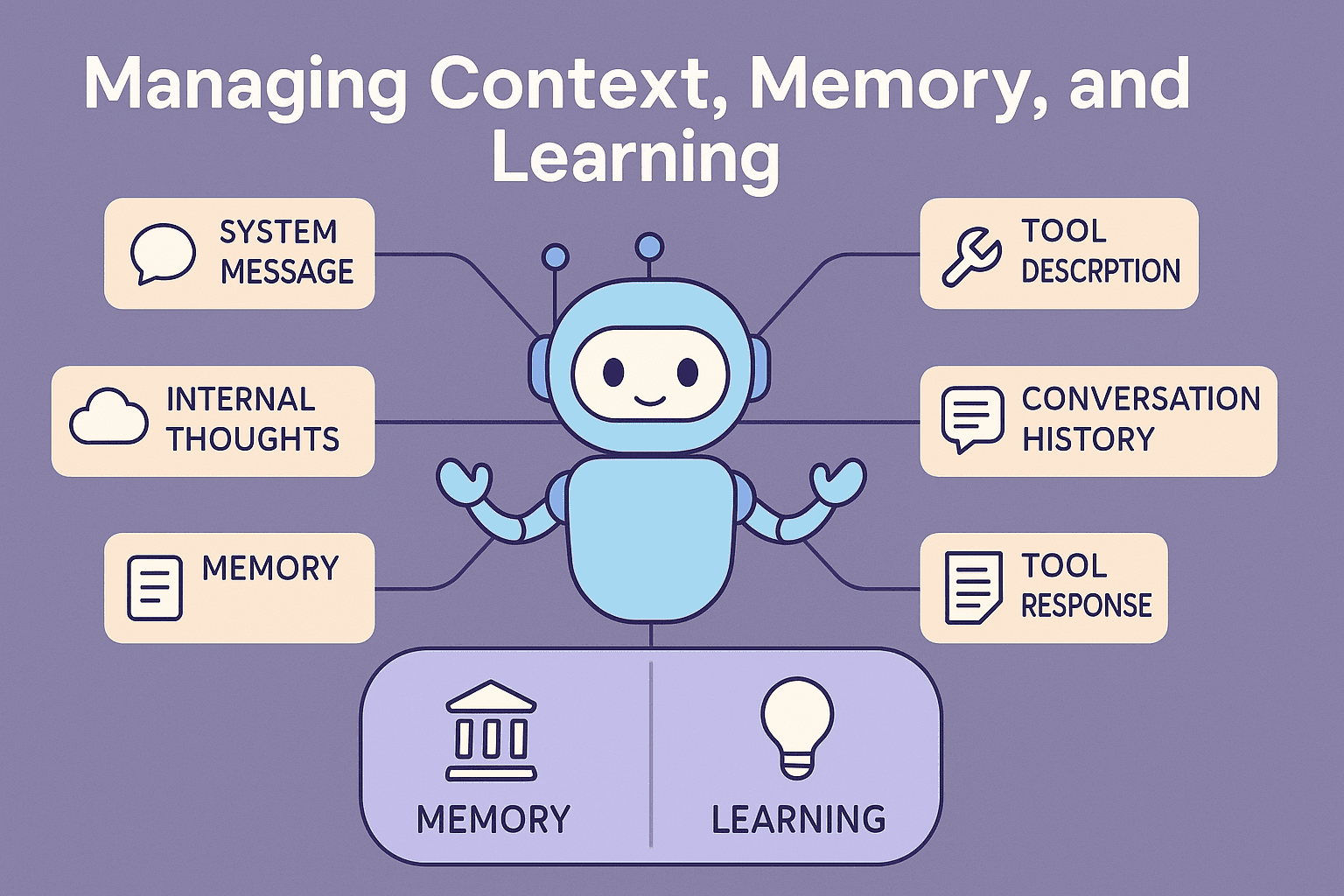
For an LLM, context is everything it receives to generate a response:
System messages (instructions)
Tool descriptions
Conversation history
Tool responses
Even its own “internal thoughts”
How you manage this context defines:
The personality of the agent
Its consistency and accuracy
And ultimately, how well it delights your users
Why Context Matters
The ability of an agent to deliver results and to feel trustworthy depends more on context than on the model itself.
Context is the foundation of the agent’s identity, personality, and responsibilities, and most importantly its ability to make the user happy:
Personality & Voice → Context defines who the agent is. Without consistent prompts and framing, tone drifts and the agent feels incoherent.
Continuity of Thought → LLMs don’t think persistently; they simulate reasoning turn by turn. Context is the bridge that makes an agent appear continuous instead of starting over each time.
Shared Understanding → Context carries the conversation state: which tools were used, what the goal is, what’s already been decided. Without it, the user has to re-explain, which kills trust.
Boundaries of Expertise → By constraining instructions and tools, context defines what an agent should and shouldn’t attempt. That prevents overreach and hallucinations.
User Experience Consistency → Users don’t judge the LLM; they judge whether the agent “gets them.” Context is what remembers preferences, adapts, and keeps interactions smooth.
👉 Put simply: context isn’t just input. It’s the agent’s memory, personality, boundaries, and shared understanding with the user. Without it, the agent isn’t really an agent — it’s just a one-off prompt.
How to Build Prompts and Tool Descriptions
There’s a lot of content in the wild on prompt engineering (here’s a good prompt guide), but not nearly enough has been said about tool instructions and descriptions. In practice, I’ve found this to be one of the hardest areas to get right.
In the past, users read the manuals. They figured out workflows, experimented, and learned the system themselves.
Now, that job shifts to the LLM. The model must “read the manual” through your tool descriptions, understand what each tool does, and use them correctly. The level of detail required isn’t always obvious which makes testing and iteration critical.
Example: imagine a Quote Agent that helps create and edit customer quotes. The agent doesn’t learn workflows from a user guide — it depends entirely on tool descriptions like quote.add_line_item or quote.set_delivery_date. If those descriptions are vague, the agent stumbles.
What this means
Documentation becomes prompts and tool descriptions.
These descriptions should live in their own files or repositories, but remain tightly coupled to the tool they describe.
Treat them as living artifacts — versioned, reviewed, and tested like code.
Common Challenges with Tool Descriptions
1. Complex parameters
Problem: The LLM fails to generate valid inputs, forcing it to ask the user too many clarifying questions.
Solution: Keep tools and parameters simple. Create tools with clear, narrow responsibilities. (I dive deeper into this in the Agent Architecture article.)
2. Overlapping responsibilities
Problem: Tools with similar or unclear scopes confuse the agent. It may pick the wrong one and fail to complete its task.
Solution: Define exclusive domains for tools. Be explicit about when and why each tool should be used.
An exclusive domain means each tool has a clear, non-overlapping area of responsibility, so the agent doesn’t have to guess between multiple tools that “sort of” do the same thing.
Think of it like team roles: if two employees both think they’re responsible for scheduling meetings, you’ll get duplication or confusion. Same with tools.
How to define it
When designing tools, write down:
Purpose → What specific outcome this tool achieves.
* Scope → What it doesn’t do. If another tool covers that, this one must stay out.
* Trigger conditions → When the agent should call it (e.g., “use this tool when the user wants to create a new quote, not when editing an existing one”).
3. Capability & description drift
Problem: Descriptions and tool code often live in different places, owned by different people. When one changes without the other, the agent gets confused — outcomes don’t match the instructions.
Solution: Co-locate responsibility. Update code and descriptions together. Build processes that make drift visible (e.g., testing generated plans against descriptions).
👉 Pro tip: Treat prompts and tool descriptions as first-class code artifacts — with versioning, testing, and clear ownership. Don’t let them live as throwaway comments; they’re the interface between your system and your agent.
The Challenge of Token Limits
Once prompts and tool descriptions are solid, the next constraint you’ll hit is the model’s token limit.
LLMs have hard context windows. You can’t keep everything in context. Long Prompts, long descriptions, a long message history, all the data coming back from the tools, files it has read, web search content it has found, and all internal thoughts are part of the context. It fills up pretty quickly.
Managing context is a significant challenge and has a big impact on the agents effectiveness.
Strategies
FIFO truncation: Keep only the most recent messages. Simple, but loses long-term awareness.
Topic-aware summarization: Summarize past exchanges by topic. When the user switches back, the summary brings the relevant history forward.
Hybrid: Recent messages stay raw; older ones collapse into summaries.
👉 The goal is focus: give the model exactly what it needs for the current task, nothing more.
Semantic and Episodic Memory
Context management doesn’t end at the prompt. Agents need memory to learn from experience, feel reliable and personal.
⚠️ Note: Memory is not naturally limited to a single thread or session. It’s technically unbounded — you could design it to span users, teams, projects, or even tenants. That flexibility is powerful, but it also means you must enforce explicit boundaries and retention policies to stay within privacy, regulatory, and data sovereignty requirements.
Semantic Memory (facts & awareness)
Stores facts about users, teams, or projects.
Lets the agent adapt to preferences, roles, and organizational context.
Can be scoped at user, team, or org levels.
Stored in vector databases (e.g., Elastic, Weaviate, Pinecone).
Example:
“This user prefers concise answers.”
“Team A is working on Project X; Bob owns feature Y.”
Episodic Memory (experience & learning)
Captures experiences as episodes: subject + actions + results.
Lets the agent learn from past outcomes and apply them in similar situations.
Can be leveraged to convert a new user request into a few-shot prompt or chain-of-thought (CoT) reusing the successful steps from a prior interaction to accomplish a similar goal.
Built from conversation parsing, sentiment analysis, and conclusion markers (“that worked”, “let’s move on”).
Stored in vector stores for retrieval in future sessions.

Example:
“Last time the user asked for a resource plan, the timeline format was off — next time, use Gantt style.”
👉 This way, episodic memory isn’t just “remembering experiences” — it becomes structured training data for the agent’s next decision.
Retrieval-Augmented Generation (RAG)
RAG extends memory beyond what fits in the prompt:
Index your knowledge base into a vector store.
Let the agent retrieve relevant chunks on demand.
Feed those chunks into the context window.
This lets agents answer with organizational knowledge instead of hallucinations.
👉 At Mezzoic, ElasticSearch has proven to be the most stable and scalable option, but the space is evolving quickly.
Mezzoic’s Approach to Context
In Mezzoic, context management is built into the workflow orchestrator and MCP client layer, not bolted on afterward.
Asynchronous, event-driven updates prevent the model from being overloaded with stale or irrelevant info.
LangChain, LangGraph, and LangMem provide the tooling, but we customize them heavily. They’re powerful, but they come with performance costs.
Prompt and tool descriptions are versioned and tested alongside code, ensuring consistency.
Result:
Agents that stay focused, adaptive, and consistent without drowning in irrelevant context.
Practical Takeaways
Context is the main design problem. Treat it as first-class architecture.
Documentation becomes prompts. Maintain them like code.
Token limits force discipline. Use summarization, focus, and hybrid strategies.
Memory makes agents human-like. Semantic = facts; episodic = experience.
RAG extends knowledge. It’s the way to scale beyond what fits in context.
Build it into the platform. Don’t duct-tape context management after the fact.
Closing
LLMs aren’t limited by their intelligence — they’re limited by their context.
Get context right, and everything else becomes easier.
👉 Next in this series: Security & Trust — how to keep agents safe, scoped, and governed with the same policies as your web apps.